Reagan Mozer, Luke Miratrix, Aaron Kaufman, and Jason Anastasopoulos
Political Analysis
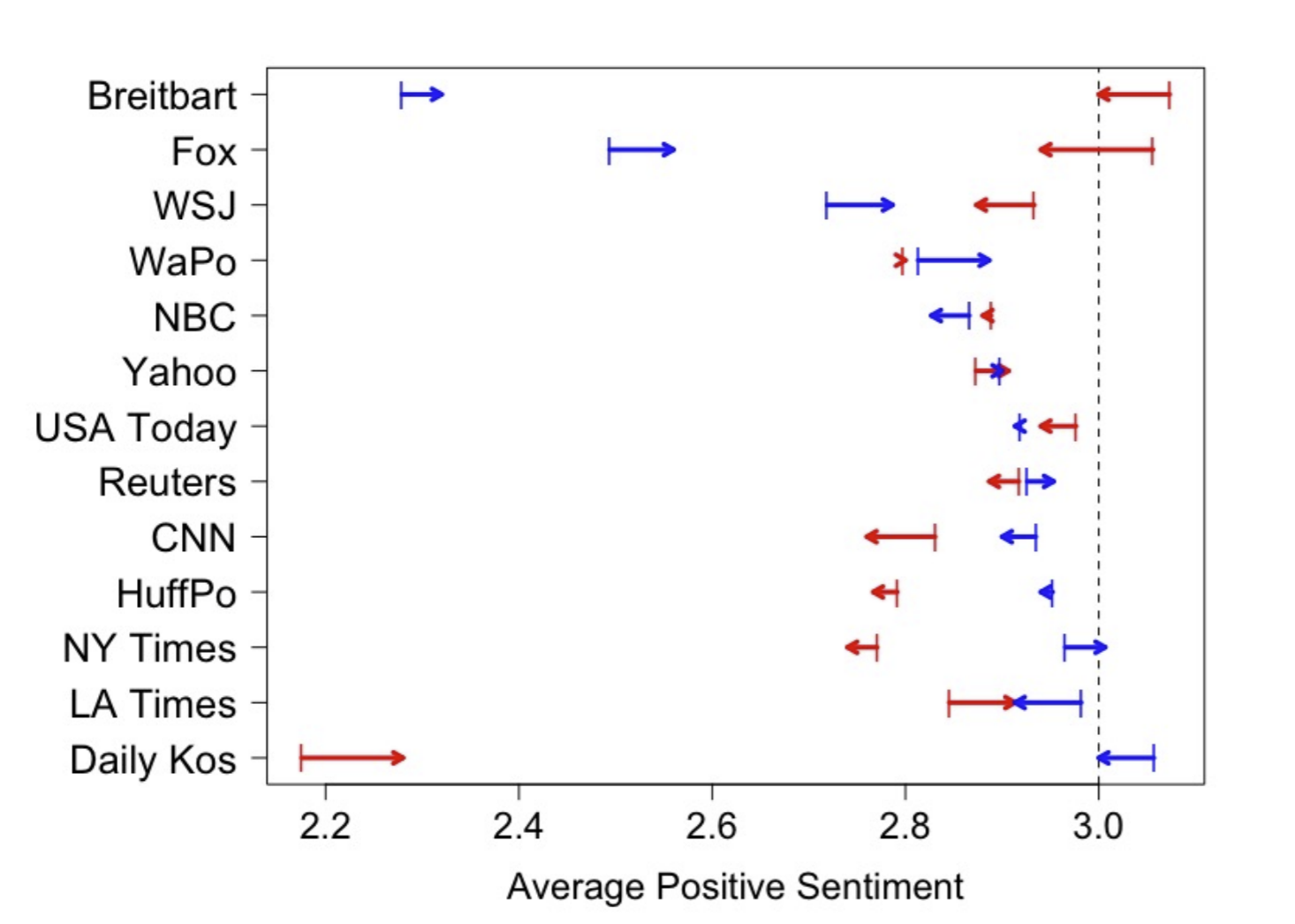
Abstract: There is little existing methodology for drawing potentially causal conclusions when pre-treatment confounders are represented by text data. Even more unclear is how to approach inference in the setting where both the pre-treatment covariates and the outcome of interest are determned by different summary measures of the same observed text. We summarize the challenges and limitations for principled analysis in this domain and propose a framework for estimating effects in studies where both the covariates and outcomes are summary measures built from text. First, we extend recent work on matching documents on features generated using text analysis methods. After matching, we estimate differential word use and sentiment using other text analysis tools. We demonstrate our procedure by comparing partisan bias across US news sources, as measured by their rates of coverage of issues and, given the same coverage, their different representation of topics. Here both the covariates (i.e., topics covered) and the outcome (i.e., language used and sentiment of covered content) are measured from the text. Our approach allows for investigation of two questions: are news sources systematically selecting different content to cover, and furthermore, when covering the same topics, are news sources presenting content using different language or sentiment?