Correcting Measurement Error Bias in Conjoint Survey Experiments
Katherine Clayton, Yusaku Horiuchi, Aaron R. Kaufman, Gary King, and Mayya Komisarchik
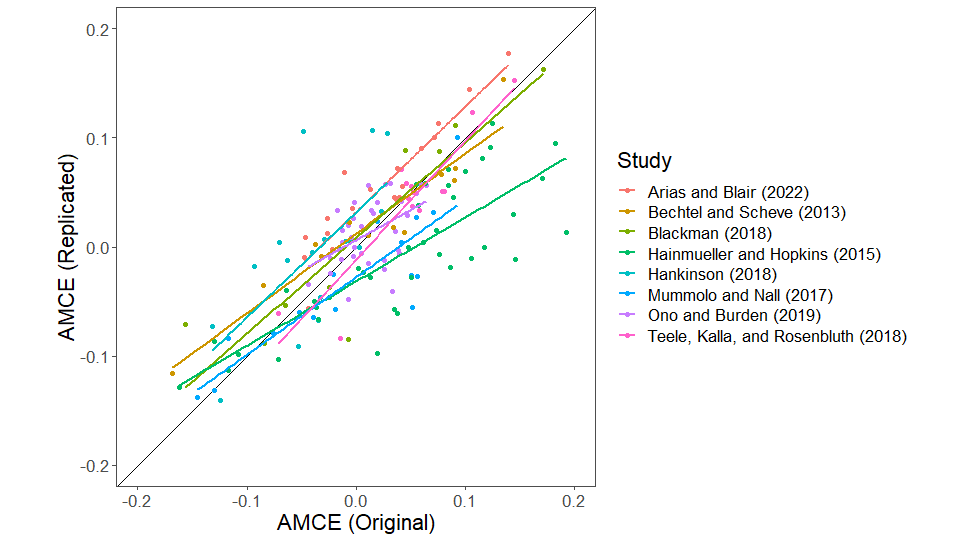
Abstract: Conjoint survey designs are spreading across the social sciences due to their unusual capacity to identify many causal effects from a single randomized experiment. Unfortunately, because the nature of conjoint designs violates aspects of best practices in questionnaire construction, they generate substantial measurement error-induced bias. By replicating both data collection and analysis of eight prominent conjoint studies, all of which closely reproduce published results, we show that about half of all observed variation in this most common type of conjoint experiment is effectively random noise. We then discover a common empirical pattern in how measurement error appears in conjoint studies and use it to derive an easy-to-use statistical method to correct the bias.
Improving Compliance in Experimental Studies of Discrimination
Aaron R. Kaufman, Christopher Celaya, and Jacob Grumbach
R&R, JOP
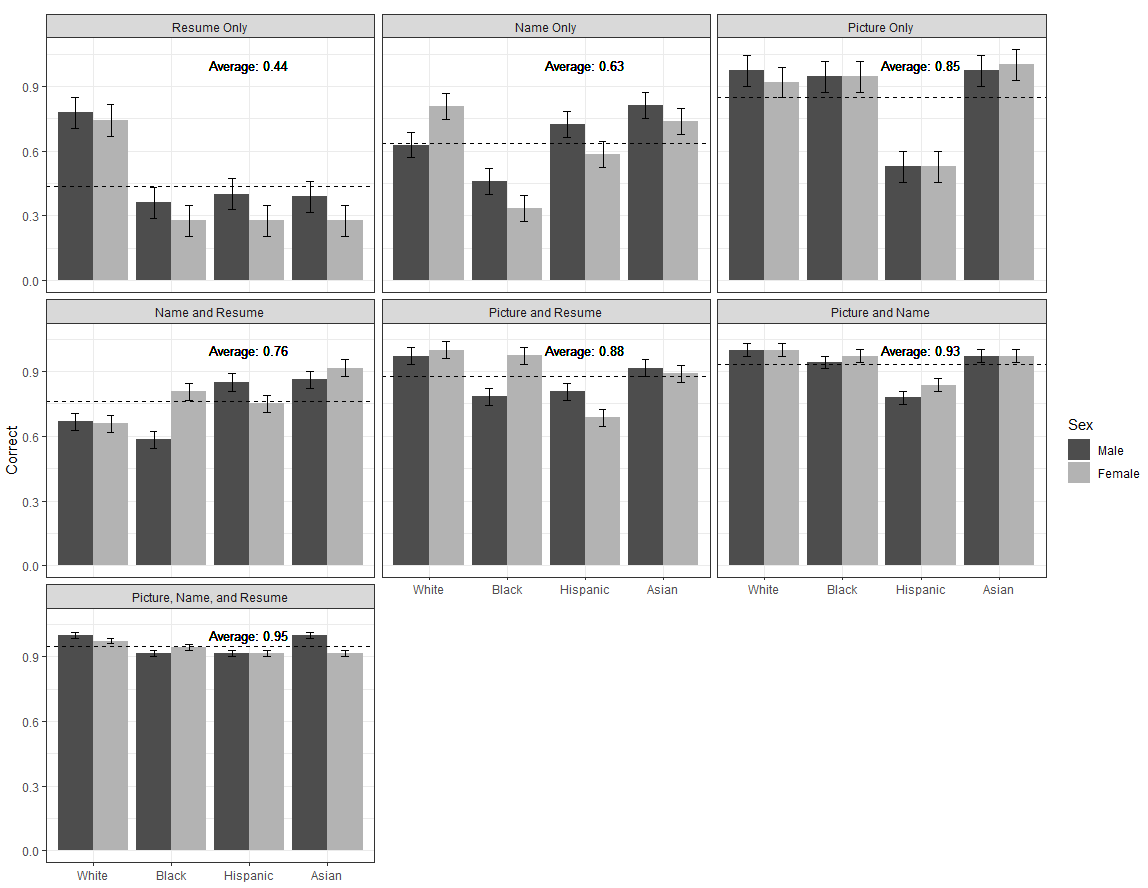
In experimental studies of discrimination, researchers often manipulate cues of social identity to isolate their discriminatory effects, holding all else constant. These studies are influential in public discourse and commonly cited in crafting anti-discrimination policy. We argue that the experimental manipulations common in these studies are prone to noncompliance: respondents do not observe, acknowledge, or update their beliefs about the social identities signaled. Focusing on experiments addressing racial discrimination, we find evidence that racialized name cues suffer from compliance as low as 33%, especially for Black treatments. Adding pre-tested racialized pictures and resume items improves compliance to 95% on average and reduces the variance in compliance across races. Our simulation studies show that this noncompliance tends to attenuate the estimated effects of race by as much as 85%, implying that racial discrimination may be much deeper than decades of audit studies have suggested.
Are Firms Gerrymandered?
Joaquin Artes, Aaron R. Kaufman, Brian Richter Kelleher, and Jeffrey Timmons
R&R, APSR
Draft available here
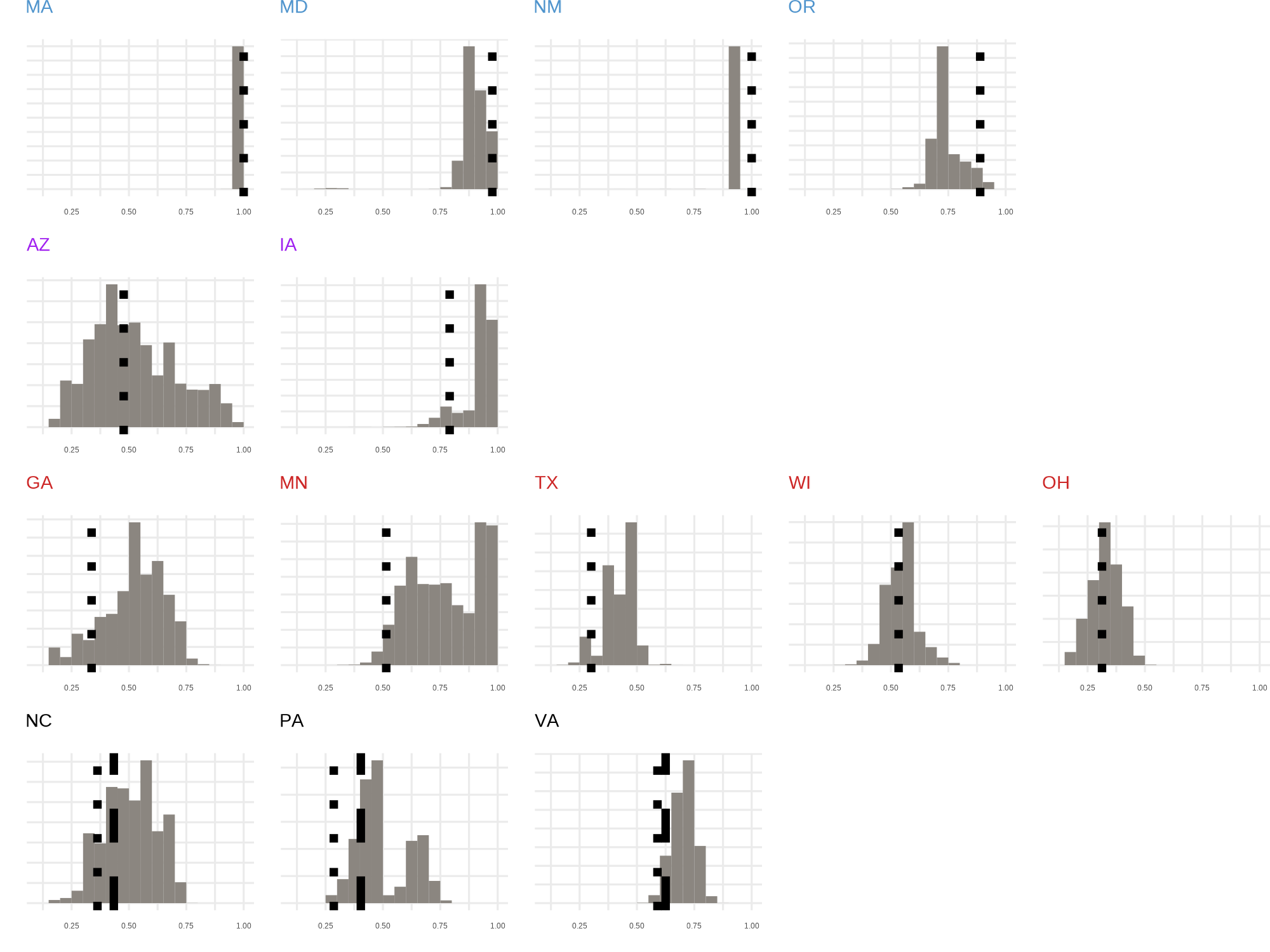
Abstract: We provide the first evidence that firms, not just voters, are gerrymandered. We compare allocations of firms in enacted redistricting plans to counterfactual distributions constructed using simulation methods. We find that firms are overallocated to districts held by the mapmakers’ party when partisans control the redistricting process. Firms are more proportionately allocated by redistricting commissions. Our results hold when we account for the gerrymandering of seats: holding fixed the number of seats the mapmakers’ party wins, firms tend to obtain more firms than expected. Our research reveals that partisan mapmakers target more than just voters.
Presidential Policymaking, 1877-2020
Aaron R. Kaufman and Jon Rogowski Revise & Resubmit, Political Science Research & Methods Abstract: While presidents frequently create new policies through unilateral power, empirical scholarship generally focuses on executive orders and overlooks other categories of directives. We use new data on more than 50,000 unilateral directives issued between 1877 and 2020 and machine learning techniques to measure their substantive importance and issue areas. Our measures reveal significant increases in unilateral activity over time, driven largely by increases in foreign affairs and through the substitution of memoranda for executive orders. We use our measures to formally evaluate the historical development of the unilateral presidency and reassess theoretical claims about public opinion and unilateral power. Our research provides new evidence about variation in and the use of presidential authority and opens new avenues for empirical inquiry.Gender Balance and Readability of COVID-19 Scientific Publishing: A Quantitative Analysis of 90,000 Preprint Manuscripts
, , , A, , , , , Releasing preprints is a popular way to hasten the speed of research but may carry hidden risks for public discourse. The COVID-19 pandemic caused by the novel SARS-CoV-2 infection highlighted the risk of rushing the publication of unvalidated findings, leading to damaging scientific miscommunication in the most extreme scenarios. Several high-profile preprints, later found to be deeply flawed, have indeed exacerbated widespread skepticism about the risks of the COVID-19 disease - at great cost to public health. Here, preprint article quality during the pandemic is examined by distinguishing papers related to COVID-19 from other research studies. Importantly, our analysis also investigated possible factors contributing to manuscript quality by assessing the relationship between preprint quality and gender balance in authorship within each research discipline. Using a comprehensive data set of preprint articles from medRxiv and bioRxiv from January to May 2020, we construct both a new index of manuscript quality including length, readability, and spelling correctness and a measure of gender mix among a manuscript's authors. We find that papers related to COVID-19 are less well-written than unrelated papers, but that this gap is significantly mitigated by teams with better gender balance, even when controlling for variation by research discipline. Beyond contributing to a systematic evaluation of scientific publishing and dissemination, our results have broader implications for gender and representation as the pandemic has led female researchers to bear more responsibility for childcare under lockdown, inducing additional stress and causing disproportionate harm to women in science. Paper here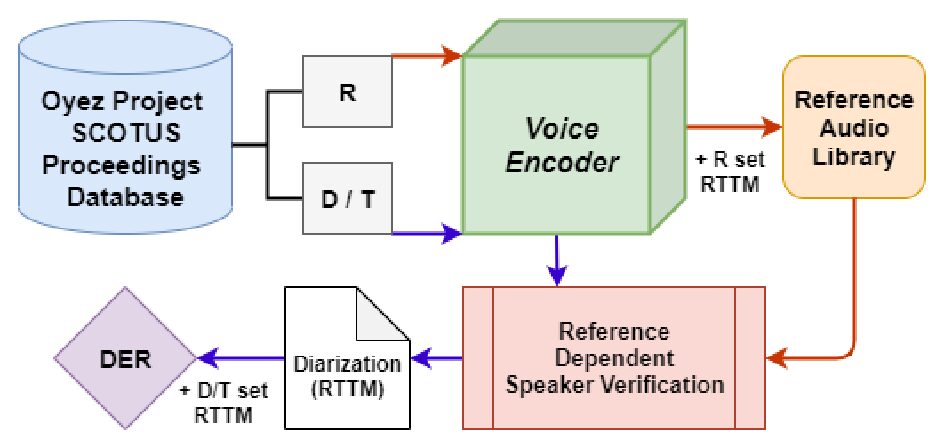
Diarization of Legal Proceedings: Identifying and Transcribing Judicial Speech from Recorded Court Audio
Jeffrey Tumminia, Amanda Kuznecov, Sophia Tsilerides, Ilana Weinstein, Brian McFee, Michael Picheny, Aaron R. Kaufman.
Under review.
United States Courts make audio recordings of oral arguments available as public record, but these recordings rarely include speaker annotations. This paper addresses the Speech Audio Diarization problem, answering the question of “Who spoke when?” in the domain of judicial oral argument proceedings. We present a workflow for diarizing the speech of judges using audio recordings of oral arguments, a process we call Reference-Dependent Speaker Verification. We utilize a speech embedding network trained with the Generalized End-to-End Loss to encode speech into d-vectors and a pre-defined reference audio library based on annotated data. We find that by encoding reference audio for speakers and full arguments and computing similarity scores we achieve a 13.8% Diarization Error Rate for speakers covered by the reference audio library on a held-out test set. We evaluate our method on the Supreme Court of the United States oral arguments, accessed through the Oyez Project, and outline future work for diarizing legal proceedings. A code repository for this research is available at github.com/JeffT13/rd-diarization.
Adaptive Fuzzy String Matching: How to Merge Data Sets with Only One (Messy) Identifying Field
Aaron R. Kaufman and Aja Klevs. Political Analysis, 2022. A single data set is rarely sufficient to address a question of substantive interest. Instead, most applied data analysis combines data from multiple sources. Very rarely do two data sets contain the same identifiers with which to merge data sets; fields like name, address, and phone number may be entered incorrectly, missing, or in dissimilar formats. Combining multiple data sets absent a unique identifier that unambiguously connects entries is called the record linkage problem. While recent work has made great progress in the case where there are many possible fields on which to match, the much harder case of only one identifying field remains unsolved: this fuzzy string matching problem, both its own problem and a component of standard record linkage problems, is our focus. We design and validate an algorithmic solution called Adaptive Fuzzy String Matching rooted in adaptive learning, and show that our tool identifies more matches, with higher precision, than existing solutions. Finally, we illustrate its validity and practical value through applications to matching organizations, places, and individuals. Ungated Online Supplement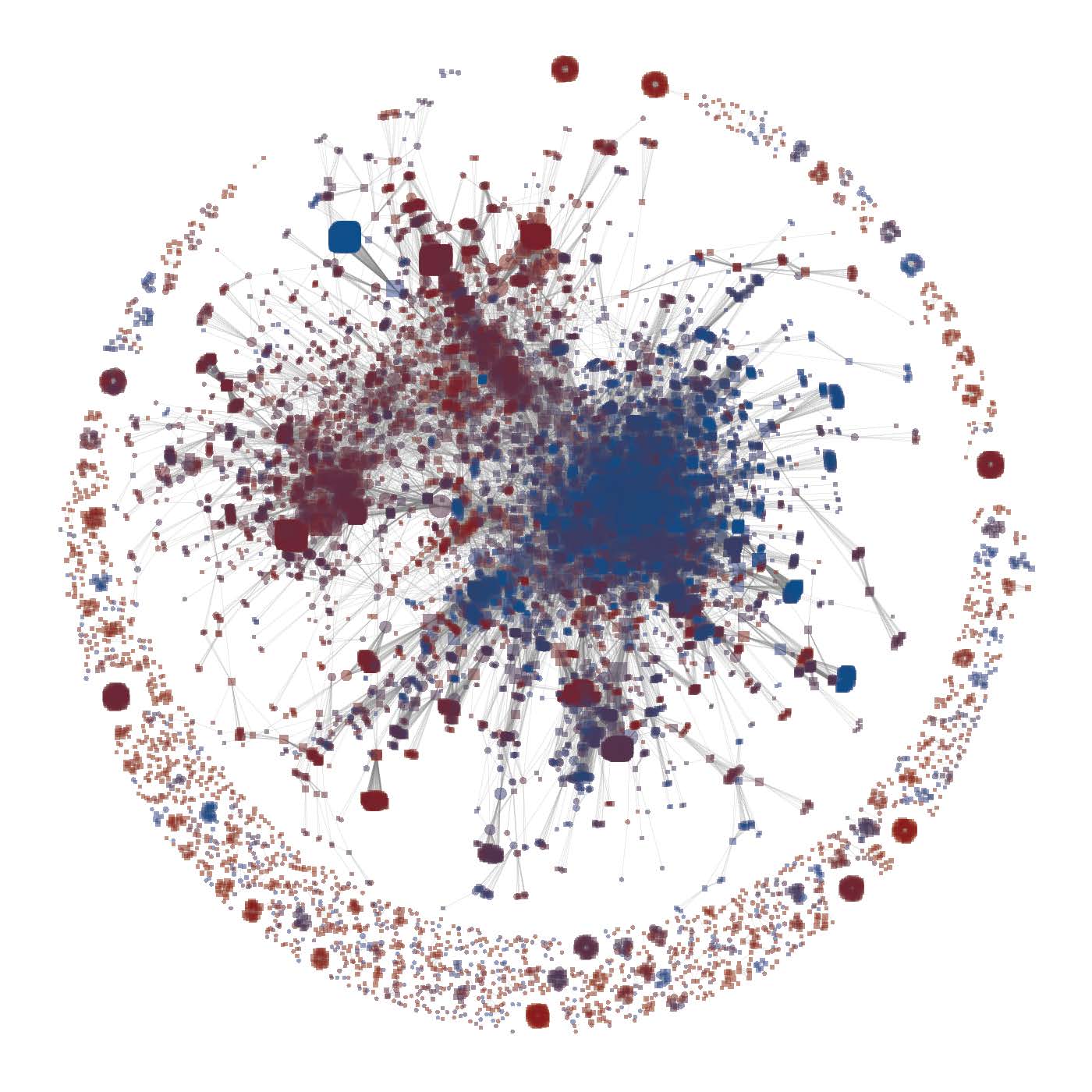
The Political Ideologies of Organized Interests: Large-Scale, Social Network Estimation of Interest Group Ideal Points
Sahar Abi-Hassan, Janet M. Box-Steffensmeier, Dino P. Christenson, Aaron R. Kaufman, and Brian Libgober.
Forthcoming at Political Analysis
Interest group influence is pervasive in American politics, impacting the function of every branch. Core to the study of interest groups, both theoretically and empirically, is the ideology of the group, yet relatively little is known on this front for the vast expanse of them. By leveraging ideal point estimation and network science, we provide a novel measure of interest group ideology for over 13,000 unique groups across almost 100 years, which provides the largest and longest measure of interest group ideologies to date. We make methodological and measurement contributions using exact matching and hand-validated fuzzy string matching to identify amicus curiae signing organizations who have given political donations and then impute and cross-validate ideal points for the organizations based on the network structure of amicus cosigning. Our empirical investigation provides insights into the dynamics of interest group macro-ideology, ideological issue domains in the Court and ideological differences between donor and non-donor organizations.
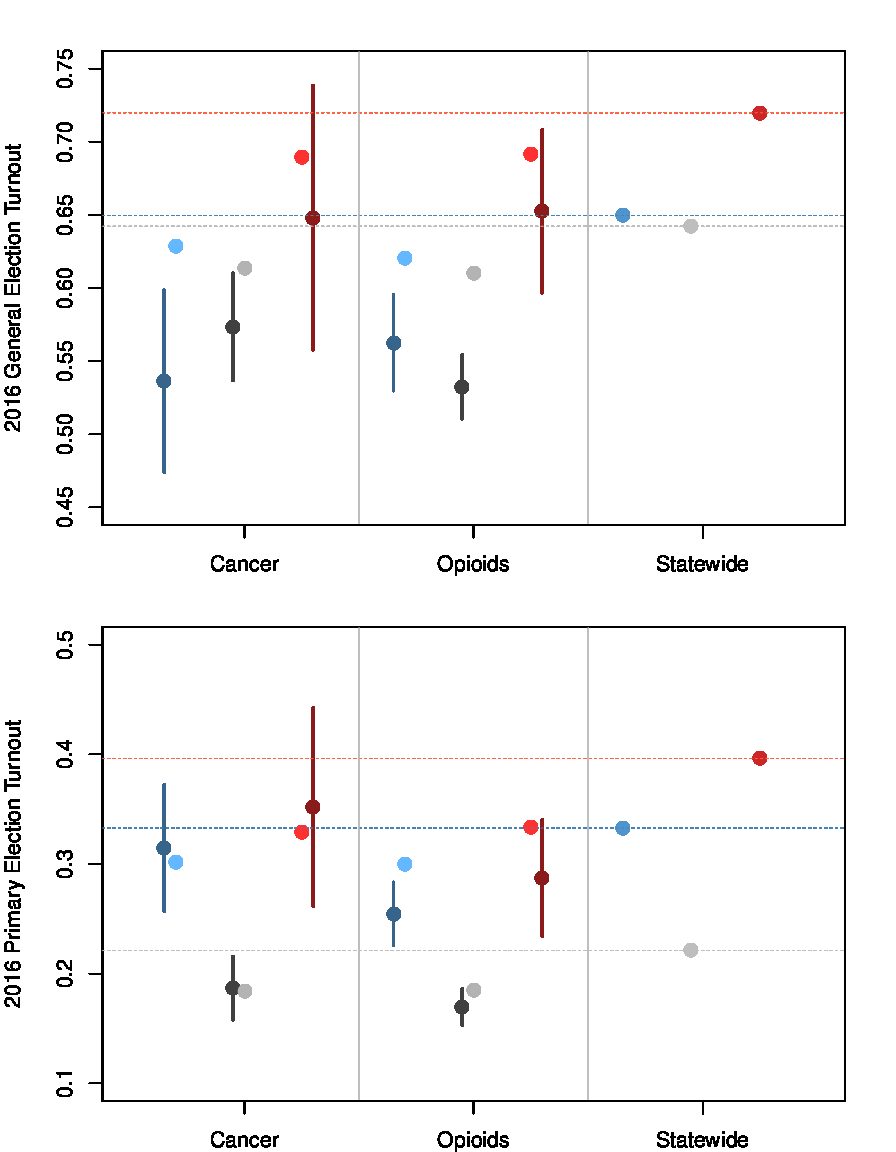
The Political Consequences of Opioid Overdoses
Aaron Kaufman & Eitan Hersh
PLoS ONE
The United States suffered a dramatic and well-documented increase in drug-related deaths from 2000 to 2018, primarily driven by prescription and non-prescription opioids, and concentrated in white and working-class areas. A growing body of research focuses on the causes, both medical and social, of this opioid crisis, but little work as yet on its larger ramifications. Using novel public records of accidental opioid deaths linked to behavioral political outcomes, we present causal analyses showing that opioid overdoses have significant political ramifications. Those close to opioid victims vote at lower rates than those less affected by the crisis, even compared to demographically-similar friends and family of other unexpected deaths. Moreover, among those friends and family affected by opioids, Republicans are 25% more likely to defect from the party than the statewide average, while Democrats are no more likely to defect; Independents are moderately more likely to register as Democrats. These results illustrate an important research design for inferring the effects of tragic events, and speak to the broad social and political consequences of what is becoming the largest public health crisis in modern United States history.
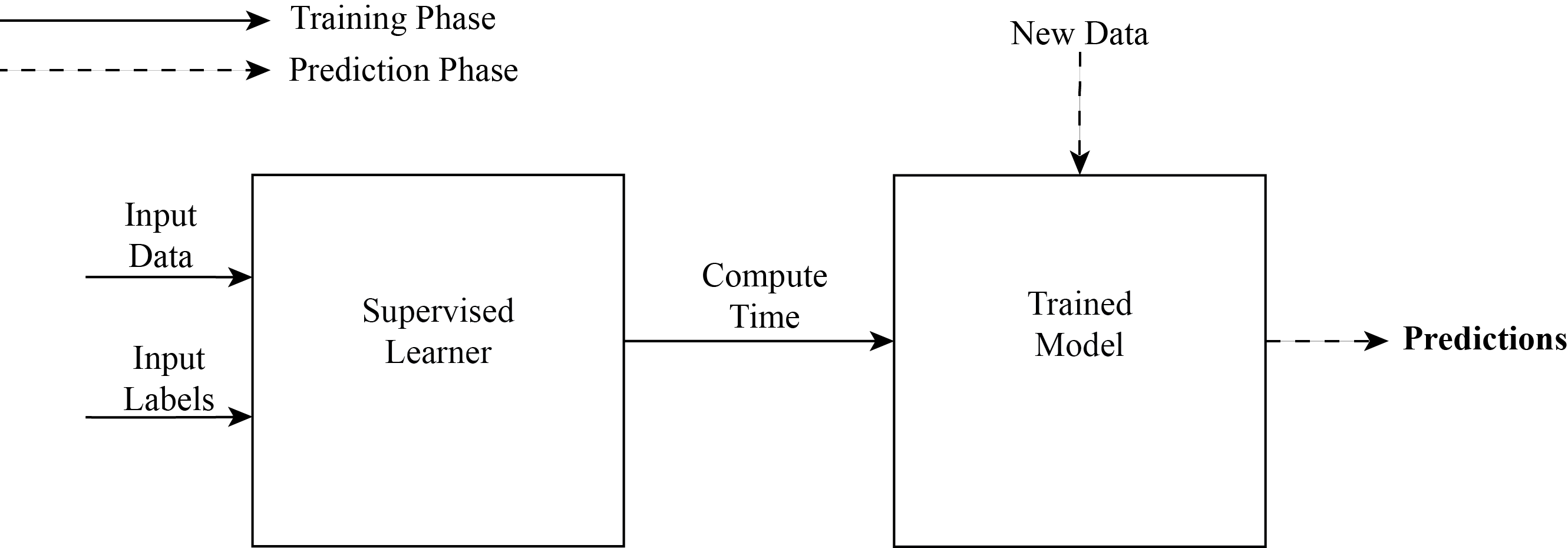
Measuring The Content of Presidential Policymaking: Applying Text Analysis to Executive Branch Directives.
Aaron Kaufman
Presidential Studies Quarterly
The executive branch produces huge quantities of text data: policy-driving documents such as executive orders, national security directives, and agency regulations; procedural documents such as notices of proposed rule-making, meeting transcripts, and presidential daily schedules; and public relations documents including press releases, veto statements, and social media posts. Political science is increasingly turning to methods of automated text analysis to rigorously interrogate such corpora. These tools have proved invaluable to scholars of the judiciary, the legislature, and of political behavior; they hold great promise for the study of the presidency and bureaucracy. These methods’ value lies in measuring complex, nuanced, yet theoretically critical quantities of interest like power, agenda setting, policy significance, ideology, and diplomatic resolve: by categorizing individual documents into a researcher-defined schema, automated text methods produce large-N data sets with fine temporal granularity. Recent work using text analysis to study unilateral actions illustrates these methods’ promise for upturning conventional wisdom, settling long-standing debates, and illuminating new puzzles in executive politics in the United States.